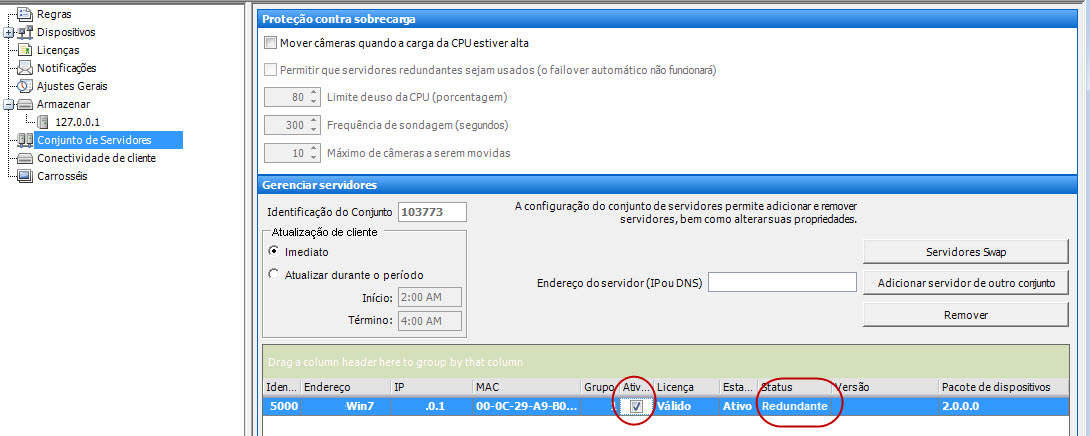
Um servidor redundante é aquele que está executando 0 câmeras. Quando um servidor é detectado como desativado, um servidor redundante é usado para substituir o processamento da câmera e do dispositivo do servidor desativado na sua totalidade. Isso significa que todas as câmeras serão movidas e executadas no servidor redundante. A perda do vídeo será baixa, de cerca de 15 segundos.
Para ativar a redundância:
• deve haver pelo menos um servidor redundante sempre disponível (um com 0 câmeras).
• o servidor redundante deve estar no mesmo Redundancy Group que o provável servidor desativado.
• a redundância deve estar definida como On nesse Redundancy Group
A redundância do grupo está ativada
|
Exemplo |
|
Configuração do conjunto de servidores: 
Exemplo – Todos os três servidores no mesmo grupo de redundância "1" Se o primeiro servidor (grupo de redundância 7) falhar, não ocorrerá nenhum failover, pois não há nenhum servidor redundante no grupo 7. 
Grupos de redundância diferentes "1" e "7" |
|
Exemplo 2 |
|
Conjunto de servidores típico do Symphony: Esta configuração representa o uso de um cluster de bancos de dados externo para redundância de dados de configuração e um NAS ou uma SAN para acesso ao arquivo de metadados de histórico após o failover. 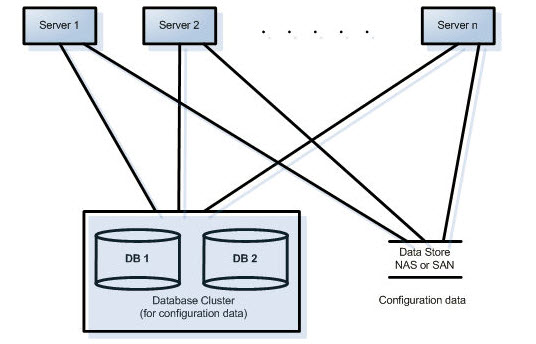
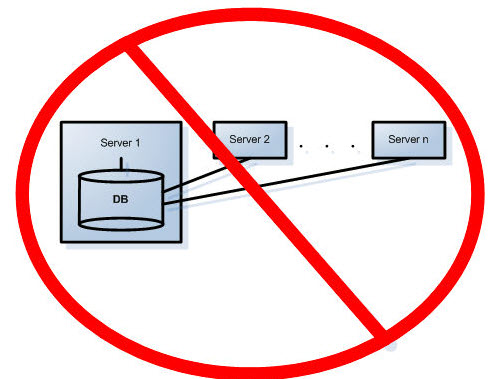
Conjunto com vários servidores com banco de dados de configuração existente em um dos Symphony Servers. Se a redundância do servidor for um requisito, essa não será uma configuração recomendada, pois ela envolve um único ponto de falha, isto é, o servidor 1. Se esse servidor falhar, a configuração não poderá ser acessada pelos servidores remanescentes.
|
Devido às restrições geográficas do armazenamento de arquivos, pode ser necessário o failover de determinados servidores somente para servidores específicos. Um grupo de redundância permite agrupar os servidores de forma que o failover ocorra somente entre os servidores do mesmo grupo. Certifique-se de que existe pelo menos um servidor redundante em cada grupo de servidores.
Um Redundancy Group utiliza um sistema de vizinho companheiro no qual cada servidor monitora a integridade de seus vizinhos (ou companheiros). Cada servidor difunde um status Alive a cada segundo, para cada um dos seus servidores companheiros, e cada servidor escuta mensagens Alive de outros vizinhos. É um gráfico de vizinhos conectados de tal forma que, se mais de um servidor estiver down, sempre haverá alguém para detectá-los.
Cada servidor executa um segmento de monitoramento que recebe mensagens do soquete UDP de cada um de seus companheiros.
• Se o tempo limite de detecção expirar sem que uma mensagem Alive seja recebida de um determinado companheiro, esse servidor poderá estar down. Uma mensagem possible down server é enviada para o servidor mestre.
• Se mais da metade dos companheiros notificarem o mestre sobre esse servidor com o status down, ele será confirmado como down. Nesse caso, um algoritmo de troca de câmera de failover assume para transferir todo o processamento de câmeras do servidor com o status down para um servidor redundante, se houver algum disponível.
A seguir encontram-se os ajustes de redundância do conjunto que podem ser configurados.
Ajustes de configuração de redundância do conjunto
|
Configuração |
Descrição |
|
FarmHealthStartDelayMs |
Na inicialização do servidor, ocorrerá este atraso antes de iniciar o monitoramento de um de seus companheiros inativos. |
|
FarmHealthSockTimeoutMs |
Os soquetes UDP são usados para receber mensagens Alive de todos os companheiros. Cada um terá este tempo limite. (Não será necessário alterar isso). |
|
FarmHealthMissedUdpMs |
O tempo em milissegundos de inatividade de um servidor antes que ele seja considerado down e o failover seja feito. Alguns clientes talvez queiram que esse tempo seja de vários minutos, permitindo que seja executada uma reinicialização do Windows Update. |
|
FarmHealthUdpPort |
Só altere esta configuração se o failover não estiver funcionando e a opção is* dos arquivos de log indicar que existem conflitos de porta. |
Essas configurações NÃO estão no banco de dados por padrão. Para adicioná-las, use as linhas a seguir. O último parâmetro é o padrão usado.
dbupdater "insert into Settings (Type,ID,Section,K,V) values ('Global','','Main','FarmHealthStartDelayMs', '5000')"
dbupdater "insert into Settings (Type,ID,Section,K,V) values ('Global','','Main','FarmHealthSockTimeoutMs', '1500')"
dbupdater "insert into Settings (Type,ID,Section,K,V) values ('Global','','Main','FarmHealthMissedUdpMs', '30000')"
dbupdater "insert into Settings (Type,ID,Section,K,V) values ('Global','','Main','FarmHealthUdpPort', '5045')"